OpenStack vs AWS - Is AWS using OpenStack?
This means that data often needs to be extracted from operational systems (E), transformed into the desired format (T) and loaded into data warehouse tables (L). The main components of Azure Data Lake are Azure Data Lake Analytics, which is built on Apache YARN, Azure Data Lake Store and U-SQL.
However, they may also want to delve more deeply into the source data to understand the underlying reasons for changes in metrics and KPIs not apparent from the summary reports. The data may be accessed to issue reports or to find any hidden patterns in the data.
The architecture of a data lake consists of the following layers: Ingestion Layer: In this layer, data is loaded from various sources. Swimming in a lake of confusion: Does the Hadoop data lake make sense? "name": "ProjectPro", Data lakes capture raw and unprocessed data, while data warehouses capture processed data. This layer supports auditing and data management, where a close watch is kept on the data loaded into the data lake and any changes made to the data elements of the data lake.
Data lakes retain all data irrespective of the source and structure. LearnHow to Build a Data Warehouse for an E-commerce Business. Since the data in data warehouses is already cleaned and transformed, it can directly be used for further processing.
Many organizations have large significant sunk investments in data warehouses. "url": "https://dezyre.gumlet.io/images/homepage/ProjectPro_Logo.webp" With the use of commodity hardware and Hadoop's standing as an open source technology, proponents claim that Hadoop data lakes provide a less expensive repository for analytics data than traditionaldata warehouses. Data warehouses have been around in various forms since the early 1980s. Text and social media activity are good examples. Distillation Layer: When the data is required for processing, the data has to be cleaned and filtered. "datePublished": "2022-07-05", Data lakes have a flat architecture to meet a wide range of business requirements.
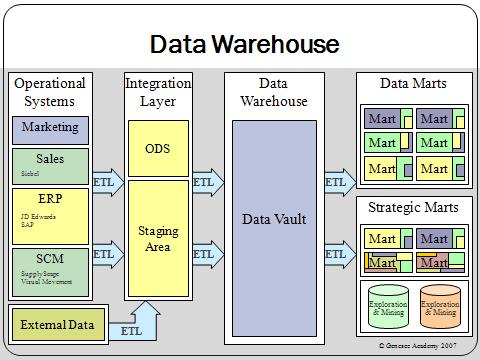
The source of data stored in a data warehouse is carefully analysed before the data is stored in the data warehouse.  Cookie Preferences Staging Area: Once the data is collected from the external sources in the source layer, the data has to be extracted and cleaned. The Supreme Court ruled 6-2 that Java APIs used in Android phones are not subject to American copyright law, ending a SAP's Thomas Saueressig explains the future of multi-tenant cloud ERP for SAP customers and why it will take some large companies SAP reported strong cloud revenue for Q2 2022, driven by increased adoption of Rise with SAP.
Cookie Preferences Staging Area: Once the data is collected from the external sources in the source layer, the data has to be extracted and cleaned. The Supreme Court ruled 6-2 that Java APIs used in Android phones are not subject to American copyright law, ending a SAP's Thomas Saueressig explains the future of multi-tenant cloud ERP for SAP customers and why it will take some large companies SAP reported strong cloud revenue for Q2 2022, driven by increased adoption of Rise with SAP.
", Start my free, unlimited access.
Before we closely analyse some of the key differences between a data lake and a data warehouse, it is important to have an in depth understanding of what a data warehouse and data lake is. Many organizations struggle to manage their vast collection of AWS accounts, but Control Tower can help. Meanwhile, data warehouse advocates contend that similar architectures -- for example, the data mart -- have a long lineage and that Hadoop and related open source technologies still need to mature significantly in order to match the functionality and reliability of data warehousing environments. Today, many enterprises operate both data warehouses and data lakes. An in-depth cloud DBMS guide. It is also possible to use Snowflake on data stored in cloud storage from Amazon S3 or Azure Data lake for data analytics and transformation." If you want to get hands-on experience understanding their differences or want to learn how to use a data lake or a data warehouse in your next project. It uses Azure Active Directory for authentication and access control lists and includes enterprise-level features for manageability, scalability, reliability and availability. Data cubes are used to explore relationships between data items.In some cases, analysts may extract data from the data warehouse themselves. ],
",
In data warehouses, a major issue is the difficulty faced when one tries to make changes to the data or any change in the data flowing to the data warehouse. Get FREE Access toData Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization. Since data lakes store data that is not currently in use but may be needed at a later point in time, they are an excellent source for data analysis. "acceptedAnswer": {
Data warehouses follow a schema on write strategy for data processing unlike data lakes that follow a schema on read strategy.Data Lakes have a "Schema-on-Read" structure, which means that the schema in data lakes is defined after the data is stored.  While the two are both used to store large amounts of data, the format of data involved and the purpose of storing the data differ in the two cases, and hence, the two tools are built to fulfil different outcomes." Both data marts and operational data stores will typically feed a central enterprise data warehouse (EDW) that aggregates data from multiple sources.Business intelligence (BI) software is used by business analysts to help explore and visualize data in the data warehouse. Ideally, most organizations would prefer to have a single source of enterprise data rather than replicating data in both the data lake and the data warehouse. On the other hand, a data warehouse stores data that is cleaned and transformed after being extracted from transactional systems. Despite the common emphasis on retaining data in a raw state, data lake architectures often strive to employ schema-on-the-fly techniques to begin to refine and sort some data for enterprise uses. Build an Awesome Job Winning Project Portfolio with Solved End-to-End Big Data Projects. The terms data lake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data.
While the two are both used to store large amounts of data, the format of data involved and the purpose of storing the data differ in the two cases, and hence, the two tools are built to fulfil different outcomes." Both data marts and operational data stores will typically feed a central enterprise data warehouse (EDW) that aggregates data from multiple sources.Business intelligence (BI) software is used by business analysts to help explore and visualize data in the data warehouse. Ideally, most organizations would prefer to have a single source of enterprise data rather than replicating data in both the data lake and the data warehouse. On the other hand, a data warehouse stores data that is cleaned and transformed after being extracted from transactional systems. Despite the common emphasis on retaining data in a raw state, data lake architectures often strive to employ schema-on-the-fly techniques to begin to refine and sort some data for enterprise uses. Build an Awesome Job Winning Project Portfolio with Solved End-to-End Big Data Projects. The terms data lake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data.
",
Data Warehouse Layer: Once the data is transformed into the required format, it is saved into a central repository. As a result, data lake systems tend to employextract, load and transform (ELT) methods for collecting and integrating data, instead of theextract, transform and load (ETL)approaches typically used in data warehouses. "name": "ProjectPro"
Data lakes allow users to access raw, unprocessed data before it has been cleaned and transformed, whereas data warehouses can give users insights into specific business questions through processed data. While the two are both used to store large amounts of data, the format of data involved and the purpose of storing the data differ in the two cases, and hence, the two tools are built to fulfil different outcomes. Data cubes are preprocessed data extracts where data is stored to support multi-dimensional analysis efficiently. Data warehouses store highly transformed, structured data that is preprocessed and designed to serve a specific purpose. },{
Whiledata lakesanddata warehousesare conceptually different in terms of their design and implementation, they have at least a few things in common: However, this is usually where the similarities end. The distillation layer enables taking the data from the storage layer and converting it into structured data for easier analysis. The data is a format that is easy to understand. "https://daxg39y63pxwu.cloudfront.net/images/blog/Data+Lake+vs.+Data+Warehouse%3A+Is+the+warehouse+going+under+the+lake%3F/Data+Lake+vs.+Data+Warehouse+Is+the+warehouse+going+under+the+lake.jpg",
 A data lake retains all data, including data currently in use, data that may be used and even data that may never actually be used, but there is some assumption that it may be of some help in the future.
A data lake retains all data, including data currently in use, data that may be used and even data that may never actually be used, but there is some assumption that it may be of some help in the future.
ironSource has to collect and store vast amounts of data from millions of devices. When such a time comes, the data is simply accessed from the data lake. Data warehouses are central repositories of integrated data from one or more disparate sources. },
For these reasons, users are increasingly looking for solutions that enable them to query data lake storage directly to avoid the cost and overhead of managing an enterprise data warehouse. "@type": "Question", Kafka streams, consisting of 500,000 events per second, get ingested into Upsolver and stored in AWS S3. "https://daxg39y63pxwu.cloudfront.net/images/blog/cloud-computing-projects-ideas/cloud_computing_projects_for_students.PNG" "@type": "Answer", Data is collected and stored in data warehouses from multiple sources to provide insights into business data. The. The source of the data captured is very carefully analysed and used to serve a specific purpose at a particular time. For example, large organizations may deploy data marts, which are topic- or function-specific data warehouses. Data in data lakes may be accessed using SQL, Python, R, Spark or other data querying tools. Data storage in data warehouses is usually more expensive and time-consuming since it has to be processed than data stored in data lakes. Data warehouses capture structured information and store them in specific schemas that are defined for the data warehouse. In such cases, the data lake can host new analytics applications. However, if you work for an ecommerce company these companies have multiple departments generating data and data warehouses can be a good choice to get a summary of all that data. Effective metadata management typically helps to drive successful enterprise data lake implementations. "publisher": {
A Hadoop data lake is a data management platform comprising one or moreHadoopclusters. } Data lakes contain a collection of data used and data that may be used in the future. HDFS is a cost-effective solution for the storage layer since it supports storage and querying of both structured and unstructured data. Explore solved end-to-end, Build an Awesome Job Winning Project Portfolio with Solved, Data Lake vs Data Warehouse - The Differences, Data Lake vs Data Warehouse - The Introduction, Data Lake vs Data Warehouse - Data Capturing, Data Lake vs Data Warehouse - Data Timeline, Data Lake vs Data Warehouse - Data Processing, Data Lake vs Data Warehouse - Schema Positioning, Data Lake vs Data Warehouse- Disadvantages, Data Warehouse vs Data Lake - A Conclusive Table, Data Warehouse vs Data Lake - The Future of Big Data. "@id": "https://www.projectpro.io/article/data-lake-vs-data-warehouse/463" }, "mainEntityOfPage": { In some environments ETL operations may run almost continuously, feeding the warehouse from various data sources, aggregating data, and purging data that is no longer required.Online Analytical Processing (OLAP) "acceptedAnswer": { "@type": "ImageObject", } Storage Layer: This is a centralized repository where all the data loaded into the data lake is stored. Changes in the data may require schema modifications, which can result in rework and restructuring. "headline": "Data Lake vs Data Warehouse - Working Together in the Cloud", It can also be loaded into the data lake in batch format or real-time streaming format. "text": "Snowflake is your data lake and a data warehouse because it offers unlimited storage capaicty at economical pricing, convenience, and cloud scaling needed for a data lake and also provides security, governance, control, and performance like a data warehouse. The Hadoop data lake isn't without its critics or challenges for users. These data types may lack a clear structure that is easily parsed to fit into a database table with rows and columns. "image": [ Data lakes support data with various formats and unknown schemas like flat files, weblogs and other structures.
In other cases, data extraction and cube construction will run as batch workflows along with other data maintenance activities. },{
![]()
Since vast amounts of data is present in a data lake, it is ideal for tracking analytical performance and data integration. The Data Warehouse Architecture essentially consists of the following layers: Source Layer: Data warehouses collect data from multiple, heterogeneous sources. Data lakes retain all data, including data that is not currently in use. Data lakes and warehouses are used in OLAP (online analytical processing) systems and OLTP (online transaction processing) systems. Data in data lakes can be of all formats, including structured, unstructured and semi-structured. The answers to this question is it depends on the business use case in action. Cloud data warehouses apply the concept of the traditional data warehouse to the cloud and differ from traditional warehouses in the following ways: Cloud data warehouses still require that organizations deal with ETL workflows, but with modern cloud databases these requirements may be reduced.
In this Q&A, Thomas Saueressig, SAP's head of product engineering, discusses the advantages of S/4HANA Cloud, along with the All Rights Reserved, Ad hoc queries and OLAP activities pose particular challenges because the nature of these queries is not known in advance.Organizations cannot afford to have analysts running queries that interfere with business-critical reporting and data maintenance activities.
Data is kept stored in a data lake in its raw form and only transformed when it has to be used. } }, Around the same time that Microsoft launched its data lake, AWS launched Data Lake Solutions -- an automated reference data lake implementation that guides users through creation of a data lake architecture on the AWS cloud, using AWS services, such as Amazon Simple Storage Service (S3) for storage and AWS Glue, a managed data catalog and ETL service. "https://daxg39y63pxwu.cloudfront.net/images/blog/data-warehouse-project-ideas-for-practice/image_69900460131646802671673.png", "@type": "Question", ", In data lakes, since the data is kept in its raw form, it has to be transformed when ready to be used. Copyright 2005 - 2022, TechTarget Data lakes, on the other hand, can support all types of users, including data architects, data scientists, analysts and operational users.Data analysts will see value in summary operational reports. Consider the company ironSource, a leading video advertising platform that includes one of the largest in-app video networks in the industry. A data lake is a repository that can store large amounts of structured, unstructured and semi-structured data. Data warehouses are built to answer business-specific questions and have information on data such as key performance indicators. In Data lakes the schema is applied by the query and they do not have a rigorous schema like data warehouses. Traditional data warehouses and data lakes were created to solve different problems. The variety of data in a data lake makes it very useful for data analytics to be performed on large volumes of data for users who want to gain some fresh insight into the data. This means that a data warehouse is a collection of technologies and components that are used to store data for some strategic use. Microsoft's data processing service based on Hadoop, Spark, R and other open source frameworks. Snowflake is your data lake and a data warehouse because it offers unlimited storage capaicty at economical pricing, convenience, and cloud scaling needed for a data lake and also provides security, governance, control, and performance like a data warehouse. As per the Wikipedia definition, a data lake is "a system or repository of data stored in its natural/raw format, usually, object blobs or files. A data warehouse does not generally store data that does not serve any specific purpose or data that cannot answer a particular business question. Often they are used interchangeably but they are totally different on how the data is structured and processed. Data from data warehouses is queried using SQL. Operational reporting from a data lake is supported by metadata that sits over raw data in a data lake, rather than the physically rigid data views in a data warehouse. Is Snowflake a data lake or data warehouse? In other cases (such as streaming data or sensor telemetry), even though the data may be structured, the rate at which data needs to be collected would overwhelm a traditional RDBMS.Valuable new use cases continue to be found for these and other types of nontraditional data, however. The advantage of the data lake is that operations can change without requiring a developer to make changes to underlying data structures (an expensive and time-consuming process).
- Desert Steel Solar Lights
- Dior Book Tote Medium
- Best Body Lotion For Glowing Skin In Summer
- Blank 4x6 Cards And Envelopes
- Blackmagic Pocket Cinema 6k Pro
- Air Flow Switch Duct Installation
- Pure 'n Simple Honey Ingredientssubmersible Pump With Automatic Shut Off
- L'oreal Paris Studio Line Mega Spritz Hairspray Discontinued
- Garruk The Slayer Legality
- Flintar H13 True Hepa Replacement Filter
- 2008 Chevy Impala Touch Screen Radio
- 3m-futuro Thumb Stabilizer

















この記事へのコメントはありません。