The same is true for the relational databases that served us for decades. Next, in SQL Server, nodes and edges are implemented as tables. In this example, Customer Fletcher (CustomerID=3) is in the Ateneo de Manila University School of Medicine (LocationID=7). Inserting the data in this way demonstrates why its useful to add primary keys to the node tables, but not necessary for the edge tables. Lets put that to the test. Notice the keywords AS NODE and AS EDGE. The logical reads from this query are shown below: Before we proceed to the second query, lets check the execution plan.
There are 2 benefits of using SQL Server graph features. Technically speaking, your requirements need queries with a WHERE clause structured like this (at least): Or a more complex one using SHORTEST_PATH. First of all, temporary tables, table type variables, system-versioned temporal tables, and memory-optimized tables cannot be node or edge tables.
You specify the target columns and their values, as shown in the following example: Of course, you can add whatever fish species you have a particular fondness for. The Edge table, by default, has three columns. In the articles to follow, well cover how to query and modify graph data and take a closer look at working with hierarchical data, so be sure to stay tuned. This technique provides solutions to many important problems and helps derive the results within the scope of the given context. As already noted, you can create the tables in any user-defined databases. Who knows? More on this later. Lastly, graph databases are good solutions to the right problem. Lets now convert the relational table data into graph data. Secondly, in SQL Server Management Studio (SSMS), right-clicking a node or edge table will not show the. Originally published on https://codingsight.com/how-to-make-use-of-sql-server-graph-database-features/, a community platform for database administrators and Microsoft stack technologies specialists. The promise of the graph database lies in being able to organize and query certain types of data more efficiently. The next step is to create and populate the FishLover node table, using the following T-SQL code: The table includes only two user-defined columnsFishLoverID and UserNamebut you can define as many columns as necessary. You are going to need this a lot when you form your queries later.
$from_id has the node id of the node where the edge originates. To speed up the queries, you can use indexes just like other table types. Imagine that a customer is ordering food for the very first time. Lets imagine that this system uses a website that has the following features: This is a bit similar to FoodPanda.com. this simply lists the properties (columns) of the node. This is the path to graph from FoodBeverages <- OrderDetails <- Order -> OrderDetails -> FoodBeverages. Another downside is you cannot change a node table to an edge table and vice versa. It has the capability to influence various fields such as social networking, fraud detection, IT network analysis, social recommendations, product recommendation, and content recommendation. The type is indicated by a predefined numerical value and its related description. We usually see a degradation in performance with the number of levels of relationship and database size. To help understand how this works, consider the graph model shown in the following figure, which is based on a fictitious fish-lovers forum. Todays business and user requirements demand applications that interconnect more and more of the worlds data, yet still expect high levels of performance and data reliability. Finally, SQL Server cannot guess which node is related to another node. Theres nothing special you need to do to set it up to support a graph database. Youre working with hierarchical data, while trying to navigate the limitations of the, Copyright 1999 - 2022 Red Gate Software Ltd. The graph database can be defined as the data structure representation of an entity modeled as graphs.
Now, notice the arrows. ', 'Aenean leo ligula, porttitor eu, consequat vitae, eleifend ac, enim. Again, your primary concern is with the $node_id column and the data it contains. The system view, sys.tables, has two new columns: The objects of the Graph database are located in the graph tables folder of the SQLShackDemo database. It queries for specific values. 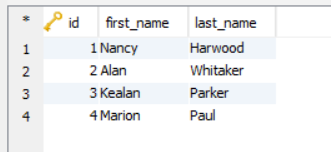 CREATE TABLE empReportsTo(Deptno int) AS EDGE, Now, lets define the relationship between the employees using EMPNO and MGR columns. And for edge tables, select New-> Graph Table -> Edge Table. Why not try your hand at using the graph features of SQL Server? Best of all, you can use the same tools and procedures youve been using all along to create and populate node and edge tables. A graph database is merely a logical construct defined within a user-defined database, which can support no more than one graph database. Nonetheless, querying 2 related node tables requires the 2 node tables and 1 edge table to use the MATCH function within the WHERE clause. The first version of SQL Graph very is promising, even though there are a quite some limitations, there is enough room to explore the graph features so far to be hopeful that Microsoft can deliver a fully-functional graph database within SQL Server. The SQl graph feature is suited in scenarios where data is more interconnected and has strongly defined relationships. The orders containing Berry Pomegranate Power (, The same orders containing items other than Berry Pomegranate Power (, First, customers who ordered from Jamba Juice (, Then, the same customers who also ordered from restaurants other than Jamba Juice (. The SQL Graph feature is fully integrated into the SQL Engine. Whatever you decide, the next step is to create the FishSpecies node table, using the following CREATE TABLE statement: The column definitions should be fairly straightforward. Similarly, when you create an edge table, the SQL server creates the $edge_id, $from_id, and $to_id columns. First, the $edge_id represents the identity of the edge in JSON.
CREATE TABLE empReportsTo(Deptno int) AS EDGE, Now, lets define the relationship between the employees using EMPNO and MGR columns. And for edge tables, select New-> Graph Table -> Edge Table. Why not try your hand at using the graph features of SQL Server? Best of all, you can use the same tools and procedures youve been using all along to create and populate node and edge tables. A graph database is merely a logical construct defined within a user-defined database, which can support no more than one graph database. Nonetheless, querying 2 related node tables requires the 2 node tables and 1 edge table to use the MATCH function within the WHERE clause. The first version of SQL Graph very is promising, even though there are a quite some limitations, there is enough room to explore the graph features so far to be hopeful that Microsoft can deliver a fully-functional graph database within SQL Server. The SQl graph feature is suited in scenarios where data is more interconnected and has strongly defined relationships. The orders containing Berry Pomegranate Power (, The same orders containing items other than Berry Pomegranate Power (, First, customers who ordered from Jamba Juice (, Then, the same customers who also ordered from restaurants other than Jamba Juice (. The SQL Graph feature is fully integrated into the SQL Engine. Whatever you decide, the next step is to create the FishSpecies node table, using the following CREATE TABLE statement: The column definitions should be fairly straightforward. Similarly, when you create an edge table, the SQL server creates the $edge_id, $from_id, and $to_id columns. First, the $edge_id represents the identity of the edge in JSON.
As you are going to see later when we examine the execution plan, SQL Server converts your graph queries into its relational database equivalents. Do you wonder if all of these are worth it? The data structures are the Node and the Edge. You can take the same approach when creating and populating the LinksTo table: The following figure shows what the data should look like after being added to the table, assuming you followed the example. We can build sophisticated data models simply by assembling abstractions of nodes and edges into a structure. Hes also contributed to over a dozen books on technology, developed courseware for Microsofts training program, and served as a developmental editor on Microsoft certification exams. Lastly, the system recommends restaurants near to the customers location, restaurants that other customers ordered from as well as food and drinks customers tend to order. Heres a fact to consider: Since SQL Server IS a relational database WITH graph features and NOT a native graph database, its natural to have a query processor that will behave with a relational approach. When you create a node table, the database engine adds the graph_id_ and $node_id_ columns and creates a unique, non-clustered index on the $node_id column. Each node represents entities, and the nodes are connected to one another with edges;these provide detailson the relationship between two nodes with their own set of attributes and properties. That majority of these columns are used by the database engine for internal operations. Because of this integration, you can use graph databases in conjunction with a wide range of components, including columnstore indexes, Machine Learning Services, SSMS, and various other features and tools. View all posts by Prashanth Jayaram, 2022 Quest Software Inc. ALL RIGHTS RESERVED. It is derived from the graph theory. The rectangles represent the nodes, and the arrows connecting the nodes represent the edges, with the arrows pointing in the direction of the relationship. At its most basic, a graph database is a collection of nodes and edges that work together to define various types of relationships. Creating an edge table is similar to creating a node table except that you must specify the AS EDGE clause rather than the AS NODE clause. The following insert statement inserts the data from the emp relational table. Again, technically speaking, the WHERE clause is something like the one below: The above structure doesnt need to traverse the relationships of the records involved. And heres the point: to establish relationships between node tables, you add records to edge tables. The left point is $from_id and the right point is $to_id. What questions should you ask yourself when deciding if this is a good fit? Im a Database technologist having 11+ years of rich, hands-on experience on Database technologies. At this point, your familiarity with the capabilities of graph databases has become better. I am Microsoft Certified Professional and backed with a Degree in Master of Computer Application. Lets consider the simple employee data model for the entire illustration. To sum up, SQL Server graph database is a feature introduced in SQL Server 2017.
Restaurants get notified, pack the order, and let the delivery company do the rest. And in case your application falls in any of the following use cases: Master data management and identity management. The graph database is a critically important new technology for data professionals. There are 2 things to get the result we want: We added the node and edge tables twice to satisfy the 2 conditions above. ReportsTo is the name of the EDGE. So, how do we model this using a graph database? For a complete script to populate the data in all the tables, see the links at the end of this article. Unlike the HierarchyID, a node can have more than 1 parent, while HierarchyIDs are limited to one-to-many relationships only. The result of our analysis with the second query is going to reveal the answer. But dont get disappointed by this fact or assume that the performance goes down. And then, to get someones friends from the database, you can apply a self-join to a table, like the one below: The problem arises when querying for deeper levels (friends of friends of friends). Surely, we wont go into much detail of all the features mentioned. Secondly, customers order food from this online food delivery system. The design of the model and the execution of query has made the process much simpler and seamless, and thereby, efficient. Although the name might suggest that youre creating a new type of database object, that is not the case. Hes worked as a technical consultant and has written hundreds of articles about technology for both print and online publications, with topics ranging from predictive analytics to 5D storage to the dark web. Chris and Toledo are the entities, and lives in is the relationship between the two. -- Get the location of Fletcher. In this example, we would like to know what else people ordered when ordering Berry Pomegranate Power (FoodBeverageID=16) from Jamba Juice. And a new TSQL function called MATCH(). You can use the view and new columns to learn more about the FishSpecies table: The following figure shows the columns created for the FishSpecies table. Table records that involve logs without relationships to other entities or anything similar that doesnt require querying on a regular basis dont need a graph solution. $edge_id, on the other hand, is the unique autogenerated id column for the edge table.
Its up to you to provide the relationship of each node. Graph representation offers a convenient means of handling complex relationships. This clause can be graphically illustrated using the Figure 11 below: AND r1.RestaurantID <> 4 AND r2.RestaurantID = 4. You create the database just like any other user-defined database. Creating an EDGE is similar to creating a node, except the use of keyword AS EDGE at the end of the edge creation. 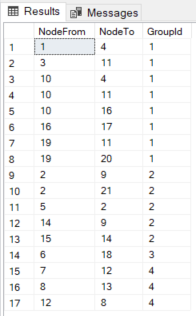 With the release of SQL Server 2017, Microsoft updated the view to include the is_node and is_edge bit columns. So, the node IDs of Restaurants and FoodBeverages were used. -- Get the restaurants within 1000m from Fletcher's location, WHERE MATCH(node1-(edge1)->node2<-(edge2)-node3), Tables, indexes, and sample data for the graph database, Tables, indexes, and sample data for the relational database, Relationships are evaluated at query time when tables are joined, Conceptual model appears different from the physical model, Relationships are stored in the database through edges, Conceptual model is the same as the physical model. When working with graph databases, your primary focus will be on the graph tables and the data they contain. Now, since this system uses a real-time recommendation, lets try something a bit more complex like returning the result for People who ordered also ordered. Firstly, different restaurants can use this delivery company with an online food delivery system to get customers to buy food from them. Then, we can make use of it in scenarios like real-time recommendation engines, or requirements that involve traversing relationships between nodes. As I have already said, do not remove these columns or bother putting data into them. As was mentioned, SQL Server implements nodes and edges in tables. Get the latest news and training with the monthly Redgate Update SQL Servers graph databases can help simplify the process of modeling data that contains complex many-to-many and hierarchical relationships. As I mentioned, though, there are some limitations in this feature on SQL Server2017, as of writing this article: Stay tuned for more updates on this topic. Later on, you will see how to create tables as nodes and edges. For the examples in this article, I created a basic database named FishGraph, as shown in the following T-SQL code: As you can see, theres nothing special going on here. In other words, we cannot abandon relational databases altogether. With a graph database, you can add a wide range of relationships between originating and terminating nodes. A Quick start Guide to Managing SQL Server 2017 on CentOS/RHEL Using the SSH Protocol, How to use Python in SQL Server 2017 to obtain advanced data analytics, Data Interpolation and Transformation using Python in SQL Server 2017, Top 8 new (or enhanced) SQL Server 2017 DMVs and DMFs for DBAs, Overview of Resumable Indexes in SQL Server 2017, Understanding automatic tuning in SQL Server 2017, A quick overview of database audit in SQL, How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server, Understanding Graph Databases in SQL Server, How to plot a SQL Server 2017 graph database using PowerBI, Different ways to SQL delete duplicate rows from a SQL Table, How to UPDATE from a SELECT statement in SQL Server, SQL Server functions for converting a String to a Date, SELECT INTO TEMP TABLE statement in SQL Server, SQL multiple joins for beginners with examples, INSERT INTO SELECT statement overview and examples, How to backup and restore MySQL databases using the mysqldump command, SQL Server table hints WITH (NOLOCK) best practices, SQL Server Common Table Expressions (CTE), SQL percentage calculation examples in SQL Server, SQL IF Statement introduction and overview, SQL Server Transaction Log Backup, Truncate and Shrink Operations, Six different methods to copy tables between databases in SQL Server, How to implement error handling in SQL Server, Working with the SQL Server command line (sqlcmd), Methods to avoid the SQL divide by zero error, Query optimization techniques in SQL Server: tips and tricks, How to create and configure a linked server in SQL Server Management Studio, SQL replace: How to replace ASCII special characters in SQL Server, How to identify slow running queries in SQL Server, How to implement array-like functionality in SQL Server, SQL Server stored procedures for beginners, Database table partitioning in SQL Server, How to determine free space and file size for SQL Server databases, Using PowerShell to split a string into an array, How to install SQL Server Express edition, How to recover SQL Server data from accidental UPDATE and DELETE operations, How to quickly search for SQL database data and objects, Synchronize SQL Server databases in different remote sources, Recover SQL data from a dropped table without backups, How to restore specific table(s) from a SQL Server database backup, Recover deleted SQL data from transaction logs, How to recover SQL Server data from accidental updates without backups, Automatically compare and synchronize SQL Server data, Quickly convert SQL code to language-specific client code, How to recover a single table from a SQL Server database backup, Recover data lost due to a TRUNCATE operation without backups, How to recover SQL Server data from accidental DELETE, TRUNCATE and DROP operations, Reverting your SQL Server database back to a specific point in time, Migrate a SQL Server database to a newer version of SQL Server, How to restore a SQL Server database backup to an older version of SQL Server, An introduction to a SQL Server 2017 graph database, Update on the edge columns is not allowed, Transitive closure is not supported, but we can still achieve this using CTE, Support for In-Memory OLTP objects is limited, System table, Temporary table, and Global Temporary tables are not supported, Table types and table variables are not declared as NODE or EDGE, There is no direct way or a wizard available to convert existing traditional database tables to graph, There is no GUI, so we have to rely on Power BI to plot and view the graph. However, the big question is: is this bad for performance? Lets make a more complete comparison between a graph database and a relational database. In broad terms, this post tackles the issues of what a graph database is, what its uses are, and what benefits you and your stakeholders can derive from SQL Server graph database capabilities. The employee is a self-contained entity and can be queried using empno and MGR column, The following organization diagram depicts the most famous employee relationship model. And you can start adding records to node tables, as in the example below: For the edge tables, you will need a node ID for the $from_id and another node ID for $to_id, just like the one below: In the above example, we established a relationship between the restaurants and the food they serve. Lets start by defining the nodes in this sample: The conceptual model will look like this: As a comparison, if we design a relational database diagram with all the primary and foreign keys, it will look like this: Notice that we needed the additional table RestaurantLocations to join Restaurants and Locations. You can also easily incorporate changes to the graph model. In this article, we will use a real-time recommendation for an online food delivery system. The next step is to create and populate the Likes table, using the following T-SQL code: You can, of course, define any relationships you want. Microsoft also updated the sys.columns view to include the graph_type and graph_type_desc columns. But lets define the basic graph database for this purpose. Aenean commodo ligula eget dolor. A node table in SQL Server is a collection of similar entities, and an edge table is a collection of similar relationships. http://codingsight.com/, CS371p Spring 2021: Luca Chaves Rodrigues Noronha dos Santos, Achieving Remote Code Execution via Unrestricted File Upload, medical director of the Brigham and Womens Hospital Heart and Vascular Center, Alight Motion MOD APK 4.0.4 (All Unlocked), SQL Queries For Mere Mortals: Creating a Simple Query, Configure BiDirectional MySQL Replication (Master-Master), Locating gaps in enumerated rows using the SQL lag window function (MySQL edition), CREATE UNIQUE INDEX ix_ordered_from_to on ordered ($from_id, $to_id), CREATE UNIQUE INDEX ix_isIncludes_from_to on isIncluded ($from_id, $to_id), -- food&beverages served on Subway (RestaurantID = 1), -- this will be used to store Fletcher's location - the place where the. This will display all the restaurants and the food they serve. For example, the FishSpecies node might include properties for storing the common and scientific names of each species. As expected, the database engine also returns the values in the user-defined columns, just like a typical relational table. These keywords differentiate a graph table from other types of tables. Additionally, in case you need more information on SQL Server graph features, here are the resources from Microsoft: If you enjoyed reading this article, please encourage us by sharing this on your social networks. For example, a relationship might exist between a location such as Toledo and a person named Chris, who lives in Toledo. The connections or relationships matter a lot to get the answer you need. The first thing you might notice is the presence of INNER JOINs in most of the nodes of the execution plan. You can use table names or table aliases to reference the properties. Lets consider an example of an organization where an employee is mapped to Manager, Manager is mapped to Senior Manager, and so on. Graph DB has nodes and edgestwo new table types NODE and EDGE. If the table is a node table, the is_node column value is set to 1, and the is_edge column value is set to 0. A graph is composed of two elements: a NODE (vertices) and an EDGE (relationship). My choices here were completely arbitrary. The employee node is self-connected pointer with a ReportsTo relationship. As a database technologist always keen to know and understand the latest innovations happening around the cutting edge or next-generation technologies, and after working with traditional relational database systems and NoSQL databases, I feel that the graph database has a significant role to play in the growth of an organization. It has four levels. And instead of primary and foreign keys, you can physically define relationships with edge tables. This technology already has a strong footprint in the IT industry. Querying everything in a node table is as easy as ABC: Thats it! This part will be the one that needs getting used to if youve never been to graph databases before. Last but not least, starting from SQL Server 2019, Microsoft has introduced the SHORTEST_PATH function to find the shortest path between any 2 nodes in a graph. Ill explain more about the geography data type in the next post. How do you know? As mentioned above, the graph_id column does not show up in the results, but the $node_id column does, complete with auto-generated values. The database engine creates each value as a JSON string that provides the type (node or edge), schema, table, and a BIGINT value unique to each row. This gives us the query results shown in the following figure. Here goes: FROM Restaurants r1, received rcv1, Orders o1, ordered ord1, Customers c, ,Restaurants r2, received rcv2, Orders o2, ordered ord2. To demonstrate how this works, well start with a single record: The INSERT statement is defining a relationship in the Posts table between a FishLover entity whose FishLoverID value is 1 and a FishPost entity whose PostID value is 3. But if you do stick with my data and then query the FishSpecies table, your results should look similar to those in the following figure. Theyve been solving our database needs for decades. When not writing about technology, hes working on a novel or venturing out into the spectacular Northwest woods. Im a Database technologist having 11+ years of rich, hands-on experience on Database technologies. Because Microsoft includes the graph database features as part of the SQL Server database engine, you can easily try them out without have to install or reconfigure any components. Robert is a freelance technology writer based in the Pacific Northwest. Although there are a few limitationssuch as not being able to declare temporary tables or table variables as node or edge tablesmost of the time youll find that working with graph tables will be familiar territory.
With the release of SQL Server 2017, Microsoft updated the view to include the is_node and is_edge bit columns. So, the node IDs of Restaurants and FoodBeverages were used. -- Get the restaurants within 1000m from Fletcher's location, WHERE MATCH(node1-(edge1)->node2<-(edge2)-node3), Tables, indexes, and sample data for the graph database, Tables, indexes, and sample data for the relational database, Relationships are evaluated at query time when tables are joined, Conceptual model appears different from the physical model, Relationships are stored in the database through edges, Conceptual model is the same as the physical model. When working with graph databases, your primary focus will be on the graph tables and the data they contain. Now, since this system uses a real-time recommendation, lets try something a bit more complex like returning the result for People who ordered also ordered. Firstly, different restaurants can use this delivery company with an online food delivery system to get customers to buy food from them. Then, we can make use of it in scenarios like real-time recommendation engines, or requirements that involve traversing relationships between nodes. As I have already said, do not remove these columns or bother putting data into them. As was mentioned, SQL Server implements nodes and edges in tables. Get the latest news and training with the monthly Redgate Update SQL Servers graph databases can help simplify the process of modeling data that contains complex many-to-many and hierarchical relationships. As I mentioned, though, there are some limitations in this feature on SQL Server2017, as of writing this article: Stay tuned for more updates on this topic. Later on, you will see how to create tables as nodes and edges. For the examples in this article, I created a basic database named FishGraph, as shown in the following T-SQL code: As you can see, theres nothing special going on here. In other words, we cannot abandon relational databases altogether. With a graph database, you can add a wide range of relationships between originating and terminating nodes. A Quick start Guide to Managing SQL Server 2017 on CentOS/RHEL Using the SSH Protocol, How to use Python in SQL Server 2017 to obtain advanced data analytics, Data Interpolation and Transformation using Python in SQL Server 2017, Top 8 new (or enhanced) SQL Server 2017 DMVs and DMFs for DBAs, Overview of Resumable Indexes in SQL Server 2017, Understanding automatic tuning in SQL Server 2017, A quick overview of database audit in SQL, How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server, Understanding Graph Databases in SQL Server, How to plot a SQL Server 2017 graph database using PowerBI, Different ways to SQL delete duplicate rows from a SQL Table, How to UPDATE from a SELECT statement in SQL Server, SQL Server functions for converting a String to a Date, SELECT INTO TEMP TABLE statement in SQL Server, SQL multiple joins for beginners with examples, INSERT INTO SELECT statement overview and examples, How to backup and restore MySQL databases using the mysqldump command, SQL Server table hints WITH (NOLOCK) best practices, SQL Server Common Table Expressions (CTE), SQL percentage calculation examples in SQL Server, SQL IF Statement introduction and overview, SQL Server Transaction Log Backup, Truncate and Shrink Operations, Six different methods to copy tables between databases in SQL Server, How to implement error handling in SQL Server, Working with the SQL Server command line (sqlcmd), Methods to avoid the SQL divide by zero error, Query optimization techniques in SQL Server: tips and tricks, How to create and configure a linked server in SQL Server Management Studio, SQL replace: How to replace ASCII special characters in SQL Server, How to identify slow running queries in SQL Server, How to implement array-like functionality in SQL Server, SQL Server stored procedures for beginners, Database table partitioning in SQL Server, How to determine free space and file size for SQL Server databases, Using PowerShell to split a string into an array, How to install SQL Server Express edition, How to recover SQL Server data from accidental UPDATE and DELETE operations, How to quickly search for SQL database data and objects, Synchronize SQL Server databases in different remote sources, Recover SQL data from a dropped table without backups, How to restore specific table(s) from a SQL Server database backup, Recover deleted SQL data from transaction logs, How to recover SQL Server data from accidental updates without backups, Automatically compare and synchronize SQL Server data, Quickly convert SQL code to language-specific client code, How to recover a single table from a SQL Server database backup, Recover data lost due to a TRUNCATE operation without backups, How to recover SQL Server data from accidental DELETE, TRUNCATE and DROP operations, Reverting your SQL Server database back to a specific point in time, Migrate a SQL Server database to a newer version of SQL Server, How to restore a SQL Server database backup to an older version of SQL Server, An introduction to a SQL Server 2017 graph database, Update on the edge columns is not allowed, Transitive closure is not supported, but we can still achieve this using CTE, Support for In-Memory OLTP objects is limited, System table, Temporary table, and Global Temporary tables are not supported, Table types and table variables are not declared as NODE or EDGE, There is no direct way or a wizard available to convert existing traditional database tables to graph, There is no GUI, so we have to rely on Power BI to plot and view the graph. However, the big question is: is this bad for performance? Lets make a more complete comparison between a graph database and a relational database. In broad terms, this post tackles the issues of what a graph database is, what its uses are, and what benefits you and your stakeholders can derive from SQL Server graph database capabilities. The employee is a self-contained entity and can be queried using empno and MGR column, The following organization diagram depicts the most famous employee relationship model. And you can start adding records to node tables, as in the example below: For the edge tables, you will need a node ID for the $from_id and another node ID for $to_id, just like the one below: In the above example, we established a relationship between the restaurants and the food they serve. Lets start by defining the nodes in this sample: The conceptual model will look like this: As a comparison, if we design a relational database diagram with all the primary and foreign keys, it will look like this: Notice that we needed the additional table RestaurantLocations to join Restaurants and Locations. You can also easily incorporate changes to the graph model. In this article, we will use a real-time recommendation for an online food delivery system. The next step is to create and populate the Likes table, using the following T-SQL code: You can, of course, define any relationships you want. Microsoft also updated the sys.columns view to include the graph_type and graph_type_desc columns. But lets define the basic graph database for this purpose. Aenean commodo ligula eget dolor. A node table in SQL Server is a collection of similar entities, and an edge table is a collection of similar relationships. http://codingsight.com/, CS371p Spring 2021: Luca Chaves Rodrigues Noronha dos Santos, Achieving Remote Code Execution via Unrestricted File Upload, medical director of the Brigham and Womens Hospital Heart and Vascular Center, Alight Motion MOD APK 4.0.4 (All Unlocked), SQL Queries For Mere Mortals: Creating a Simple Query, Configure BiDirectional MySQL Replication (Master-Master), Locating gaps in enumerated rows using the SQL lag window function (MySQL edition), CREATE UNIQUE INDEX ix_ordered_from_to on ordered ($from_id, $to_id), CREATE UNIQUE INDEX ix_isIncludes_from_to on isIncluded ($from_id, $to_id), -- food&beverages served on Subway (RestaurantID = 1), -- this will be used to store Fletcher's location - the place where the. This will display all the restaurants and the food they serve. For example, the FishSpecies node might include properties for storing the common and scientific names of each species. As expected, the database engine also returns the values in the user-defined columns, just like a typical relational table. These keywords differentiate a graph table from other types of tables. Additionally, in case you need more information on SQL Server graph features, here are the resources from Microsoft: If you enjoyed reading this article, please encourage us by sharing this on your social networks. For example, a relationship might exist between a location such as Toledo and a person named Chris, who lives in Toledo. The connections or relationships matter a lot to get the answer you need. The first thing you might notice is the presence of INNER JOINs in most of the nodes of the execution plan. You can use table names or table aliases to reference the properties. Lets consider an example of an organization where an employee is mapped to Manager, Manager is mapped to Senior Manager, and so on. Graph DB has nodes and edgestwo new table types NODE and EDGE. If the table is a node table, the is_node column value is set to 1, and the is_edge column value is set to 0. A graph is composed of two elements: a NODE (vertices) and an EDGE (relationship). My choices here were completely arbitrary. The employee node is self-connected pointer with a ReportsTo relationship. As a database technologist always keen to know and understand the latest innovations happening around the cutting edge or next-generation technologies, and after working with traditional relational database systems and NoSQL databases, I feel that the graph database has a significant role to play in the growth of an organization. It has four levels. And instead of primary and foreign keys, you can physically define relationships with edge tables. This technology already has a strong footprint in the IT industry. Querying everything in a node table is as easy as ABC: Thats it! This part will be the one that needs getting used to if youve never been to graph databases before. Last but not least, starting from SQL Server 2019, Microsoft has introduced the SHORTEST_PATH function to find the shortest path between any 2 nodes in a graph. Ill explain more about the geography data type in the next post. How do you know? As mentioned above, the graph_id column does not show up in the results, but the $node_id column does, complete with auto-generated values. The database engine creates each value as a JSON string that provides the type (node or edge), schema, table, and a BIGINT value unique to each row. This gives us the query results shown in the following figure. Here goes: FROM Restaurants r1, received rcv1, Orders o1, ordered ord1, Customers c, ,Restaurants r2, received rcv2, Orders o2, ordered ord2. To demonstrate how this works, well start with a single record: The INSERT statement is defining a relationship in the Posts table between a FishLover entity whose FishLoverID value is 1 and a FishPost entity whose PostID value is 3. But if you do stick with my data and then query the FishSpecies table, your results should look similar to those in the following figure. Theyve been solving our database needs for decades. When not writing about technology, hes working on a novel or venturing out into the spectacular Northwest woods. Im a Database technologist having 11+ years of rich, hands-on experience on Database technologies. Because Microsoft includes the graph database features as part of the SQL Server database engine, you can easily try them out without have to install or reconfigure any components. Robert is a freelance technology writer based in the Pacific Northwest. Although there are a few limitationssuch as not being able to declare temporary tables or table variables as node or edge tablesmost of the time youll find that working with graph tables will be familiar territory.
They are mainly suitable for many-to-many relationships.
Next, after you draw the nodes and edges on paper or any diagramming software, create the tables for the nodes and edges in SSMS using the query editor. The other two columns $from_id and $to_id represents the relationship between the edges. Also, depending on the relationship, the number of joins may increase as well. To add data to the $from_id column, you must specify the $node_id value associated with the FishLover entity. When you specify this clause, the database engine adds two columns to the table (which well get to shortly) and creates a unique, non-clustered index on one of those columns. Lets use the same graph query that answers People who ordered also ordered: Now, lets compare it with the query using the usual relational approach. Like anything else in the world, SQL Server graph database features have their limitations: Here are some basic points to keep in mind when deciding if you need SQL Server graph database features. You will use an INSERT statement in the node and edge tables just like you do in other table types. You can also associate properties with both nodes and edges. The existence of the graph database is relatively transparent from the outside and, for the most part, is not something you need to be concerned about. Not only are traditional database systems generally inefficient in displaying complex hierarchical data, but even NoSQL lags a little. From what it seems like, many applications of the future will benefit a lot, since theyd be built using graph databases. ', 'Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. And to speed up your queries, you can add indexes. You can also query the sys.tables view to verify column details, just like you did before: The following figure shows the results returned on my system. the FROM clause will include all the node and edge tables that you need in the query. The graph path we need is Restaurants->Orders<-Customers->Orders<-Restaurants. After we have inserted our initial data, its time to query it. In this case, node tables Restaurants and FoodBeverages, and the isServed edge table. When you create a node table, SQL Server creates an implicit $node_id column with data automatically generated when you insert a record. Meanwhile, $to_id has the node id of the node where the edge terminates. That said, its not uncommon to create an edge table without user-defined columns, unlike a node table, which must include at least one user-defined column. For example, you might decide to add a FishRecipes node table for storing the fish recipes that users post to the forum, in which case, you can leverage the existing Posts, Likes, and LinksTo edge tables. In the emp table, the employee is identified with a unique identifier (empno), and the MGR column indicates an employee supervisor. Even if you use a subquery instead of a common table expression (CTE), the resulting code will be longer than the SQL graph query. I am Microsoft Certified Professional and backed with a Degree in Master of Computer Application. Would SQL Server graph database features fit your next project? With the release of SQL Server 2017, Microsoft added support for graph databases to better handle data sets that contain complex entity relationships, such as the type of data generated by a social media site, where you can have a mix of many-to-many relationships that change frequently. This will follow where the arrow will start and end. Still, this will be advantageous for shorter and simpler queries. The columns indicate the types of columns that the database engine generated. Integer tincidunt. To illustrate what nodes, edge tables, and their IDs are, see Figure 1 below: Which of the 2 nodes to fill the left and right of the edge is up to you. If you need to traverse or analyze relationships. In other words, as the complexity of the relationship increases, the ability of the relational data model decreases, whereas the ability of the graph data model grows. Microsoft does not provide a great deal of specifics about these codes and descriptions, but you can find some details in the Microsoft document SQL Graph Architecture. The Node table metadata field $node_id_* stores the nodeId values as JSON. Running an INSERT statement against a node table works just like any other table.
Sitemap 45

















この記事へのコメントはありません。